LexExMachina
This page provides additional resources related to our approach LexExMachina, described in our paperBridging the gap between Ontology and Lexicon via Class-specific Association Rules Mined from a Loosely-Parallel Text-Data Corpus
Awarded for ⭐ Best Paper ⭐ Authors:
- Basil Ell - CIT-EC, Universität Bielefeld (Germany), and Department of Informatics, University of Oslo (Norway)
- Mohammad Fazleh Elahi - CIT-EC, Universität Bielefeld (Germany)
- Philipp Cimiano - CIT-EC, Universität Bielefeld (Germany)
In a nutshell
We define 20 types of association rules that help to bridge from natural language to a knowledge base and from a knowledge base to natural language. We believe that these rules are relevant for tasks such as information extraction from text (for knowledge base population), question answering over a knowledge base, verbalization of RDF data, and verbalization of SPARQL queries. We have mined ~500,000,000 rules from a corpus consisting of Wikipedia texts and the DBpedia knowledge graph. Simplified examples:
Map from NL to KB:
"Greek" + dbo:Person ⇒ dbo:nationality=dbr:Greece
"Greek" + dbo:Settlement ⇒ dbo:country=dbr:Greece
"Greek" + dbo:Model ⇒ dbo:birthplace=dbr:Greece
"Greek" + dbo:RugbyClub ⇒ dbo:location=dbr:Greece Map from KB to NL:
dbo:Writer + dbo:author ⇒ "written by"
dbo:Composer + dbo:author ⇒ "composed by"
dbo:Comedian + dbo:author ⇒ "directed by"
"Greek" + dbo:Person ⇒ dbo:nationality=dbr:Greece
"Greek" + dbo:Settlement ⇒ dbo:country=dbr:Greece
"Greek" + dbo:Model ⇒ dbo:birthplace=dbr:Greece
"Greek" + dbo:RugbyClub ⇒ dbo:location=dbr:Greece Map from KB to NL:
dbo:Writer + dbo:author ⇒ "written by"
dbo:Composer + dbo:author ⇒ "composed by"
dbo:Comedian + dbo:author ⇒ "directed by"
Abstract of our paper
There is a well-known lexical gap between content expressed in the form of natural language (NL) texts and content stored in an RDF knowledge base (KB). For tasks such as Information Extraction (IE), this gap needs to be bridged from NL to KB, so that facts extracted from text can be represented in RDF and can then be added to an RDF KB. For tasks such as Natural Language Generation, this gap needs to be bridged from KB to NL, so that facts stored in an RDF KB can be verbalized and read by humans. In this paper we propose LexExMachina, a new methodology that induces correspondences between lexical elements and KB elements by mining class-specific association rules. As an example of such an association rule, consider the rule that predicts that if the text about a person contains the token "Greek", then this person has the relation nationality to the entity Greece. Another rule predicts that if the text about a settlement contains the token "Greek", then this settlement has the relation country to the entity Greece. Such a rule can help in question answering, as it maps an adjective to the relevant KB terms, and it can help in information extraction from text. We propose and empirically investigate a set of 20 types of class-specific association rules together with different interestingness measures to rank them. We apply our method on a loosely-parallel text-data corpus that consists of data from DBpedia and texts from Wikipedia, and evaluate and provide empirical evidence for the utility of the rules for Question Answering.Example
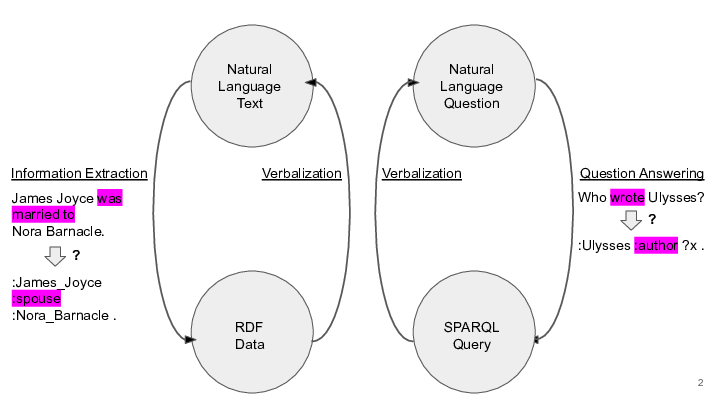
The rules that we have obtained help us to bridge the lexical gap for multiple tasks, as explained below.
Information Extraction
Given the sentence "James Joyce was married to Nora Barnacle" and given that we would like to add the information to a knowledge graph where this kind of relation is expressed via the predicate dbo:spouse, how can we connect "was married to" and dbo:spouse? Our dataset contains a class-specific association rule that enables us to bridge the gap: dbo:Writer ∈ ce and 'was married to' ∈ le(dbo:Writer,dbo:spouse,so) => ∃ o : (e, dbo:spouse, o) ∈ G In the context of information extraction, the rule can be interpreted as follows: if in a text from which we want to extract facts an entity that is an instance of the class dbo:Writer is mentioned and the text contains the token sequence "was married to", then the RDF data that represents the meaning expressed in the text will contain the predicate dbo:spouse. Thus, this rule helps us to bridge from "was married to" to dbo:spouse. For this rule we have obtained the following values (the events A and B are the left hand side and the right hand side of the association rule, respectively):| P(A|B) = | 0.9 |
| P(B|A) = | 0.016 |
| sup(A) = | 10 |
| sup(B) = | 557 |
| sup(AB) = | 9 |
| AllConf(A,B) = | 0.016 |
| CoherenceA,B) = | 0.015 |
| Cosine(A,B) = | 0.120 |
| IR(A,B) = | 0.980 |
| Kulczynski(A,B) = | 0.458 |
| MaxConf(A,B) = | 0.9 |
Verbalization of RDF data
TODO: show that there are a couple of rules that provide lexicalization options. the same applies for the verbalization of SPARQL queries.Question Answering (over an RDF knowledge base)
Given the question "Who wrote Ulysses?" and a knowledge graph where the relation that we need for building the SPARQL query is dbo:author (i.e., the correct SPARQL query is SELECT ?x WHERE { dbr:Ulysses_novel dbo:author ?x}), how to we bridge from "wrote" to dbo:author? Let's assume that we have identified the entity dbr:Ulysses_(novel) in the question, which is an instance of the class dbo:Book. Our dataset contains a class-specific association rule that enables us to bridge the gap: dbo:Book ∈ ce and 'wrote' ∈ le => ∃ o : (e, dbo:author, o) ∈ G For this rule we have obtained the following values:P(A|B) = 0.865 P(B|A) = 0.022 sup(A) = 231 sup(B) = 9039 sup(AB) = 200 AllConf(A,B) = 0.022 Coherence(A,B) = 0.021 Cosine(A,B) = 0.138 IR(A,B) = 0.971 Kulczynski(A,B) = 0.443 MaxConf(A,B) = 0.865In the context of question answering, the rule can be interpreted as follows: If the question mentions a book and contains the token "wrote", then the SPARQL query will contain the predicate dbo:author. Alternatively, let's assume that we do not know that Ulysses is an instance of the class dbo:Book or we did not even identify an entity - thus, we have no class given. In this case, we can find the following rule in our dataset: dbo:Writer ∈ ce and 'wrote' ∈ le(dbo:Writer,dbo:author,so) => ∃ s : (s, dbo:author, e) ∈ G For this rule we have obtained the following values:
P(A|B) = 1 P(B|A) = 0.006 sup(A) = 13 sup(B) = 1907 sup(AB) = 13 AllConf(A,B) = 0.006 Coherence(A,B) = 0.006 Cosine(A,B) = 0.082 IR(A,B) = 0.993 Kulczynski(A,B) = 0.503 MaxConf(A,B) = 1In the context of question answering, the rule can be interpreted as follows: We ignore the class specified in the head of the rule, because we have not found a class that is mentioned in the question and we have not found an entity in the sentence. If "wrote" occurs in the question, then the rule predicts that the predicate dbo:author occurs in the SPARQL query that corresponds to the question.
Available Resources
- Paper (metadata)
- Presentation slides from LDK conference
- Presentation video from LDK conference (coming soon)
- Code (Perl scripts, unfinished documentation)
- Data (the data that represents the loosely/parallel text-data corpus and the data created in the intermediate steps)
- Results (the rules - one file per class and rule pattern. The rules have been mined with very low threshold values. For practical purposes you might define higher threshold values and file the dataset accordingly.)
- Evaluation
- Rule Explorer (interactively filter the set of rules)
Funding Statement
This work has been supported by the EU's Horizon 2020 project Prêt-à-LLOD (grant agreement No 825182) and by the SIRIUS centre: Norwegian Research Council project No 237898.How to cite
Ell, Basil, Mohammad Fazleh Elahi, and Philipp Cimiano. "Bridging the Gap Between Ontology and Lexicon via Class-Specific Association Rules Mined from a Loosely-Parallel Text-Data Corpus." 3rd Conference on Language, Data and Knowledge (LDK 2021). Schloss Dagstuhl-Leibniz-Zentrum für Informatik, 2021.@InProceedings{ell_et_al:OASIcs.LDK.2021.33,
author = {Ell, Basil and Elahi, Mohammad Fazleh and Cimiano, Philipp},
title = {{Bridging the Gap Between Ontology and Lexicon via Class-Specific Association Rules Mined from a Loosely-Parallel Text-Data Corpus}},
booktitle = {3rd Conference on Language, Data and Knowledge (LDK 2021)},
pages = {33:1--33:21},
series = {Open Access Series in Informatics (OASIcs)},
ISBN = {978-3-95977-199-3},
ISSN = {2190-6807},
year = {2021},
volume = {93},
editor = {Gromann, Dagmar and S\'{e}rasset, Gilles and Declerck, Thierry and McCrae, John P. and Gracia, Jorge and Bosque-Gil, Julia and Bobillo, Fernando and Heinisch, Barbara},
publisher = {Schloss Dagstuhl -- Leibniz-Zentrum f{\"u}r Informatik},
address = {Dagstuhl, Germany},
URL = {https://drops.dagstuhl.de/opus/volltexte/2021/14569},
URN = {urn:nbn:de:0030-drops-145691},
doi = {10.4230/OASIcs.LDK.2021.33},
annote = {Keywords: Ontology, Lexicon, Association Rules, Pattern Mining}
}